

社内でとあるWe APIを開発中にPostgreSQLを使用してIDとして大量の連番を取得する必要がありました。1つずつ順次処理で取得したときに速度がでなかったため、高速化の方法を備忘録として残しておきます。※初~中級者向けの投稿です。
なぜ連番を取得する必要があったか
開発中のWeb APIでは、用途によってPostgreSQLとAzure Cosmos DBの2つのデータベースを使い分けていました。APIのインターフェースとしては内部のDBを意識しないようになっていて、どちらの場合もユニークなIDを同じルール (連番) で割り当てる仕様でした。 ※REST APIのPOSTの話です。
PostgreSQLだけでしたらクエリ中でシーケンスを使えばよいため特に意識する必要はありませんが、Azure Cosmos DBはシーケンスと同等の機能がなさそうだったため、PostgreSQLでシーケンスを使ってユニークなIDを発行し、そのIDでAzure Cosmos DBに登録することにしました。
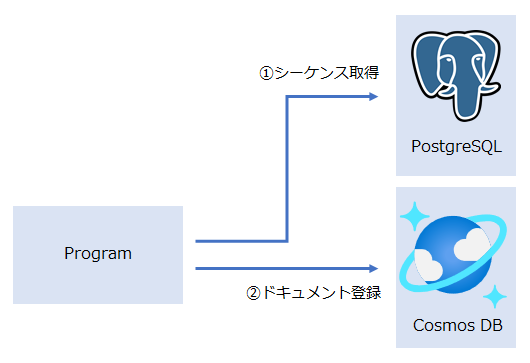
このプロジェクトでは1件のCRUD操作の他に、大量のデータを同時に登録するためにファイルをアップロードしてバッチ処理するAPIが必要でした。このバッチ処理で大量に連番を取得する必要がありました。
問題点
1件の登録処理では問題ありませんでしたが、バッチ処理を実装したところ期待していたほど速度が出ませんでした。どこが遅いかを調査した結果、IDを取得する処理が遅いことが判明しました。
例えば1000件の同時登録処理で、以下のクエリを1000回発行していたためです。
SELECT nextval('sequence_name'::regclass);解決策
クエリの発行回数を最小限にすれば良いと考え、1回のクエリで必要数分のIDを発行するアプローチで検討しました。ストアドファンクションでもできなくはないですが、nextvalをループする気持ち悪いストアドファンクションになりそうだったのでボツ。PostgreSQLのリファレンスでシーケンス操作関数を眺めていたらsetvalの返り値がbigintとなっていて、”setvalによって返される結果は単にその第 2 番目の引数の値です。” との記述がありました。シーケンスの値を設定できるのは知っていましたが、引数に設定した値が返ってくるのは知りませんでした。少し考えたらそれ返すしかないよね、とは思いましたが。。。
SELECT setval('sequence_name'::regclass, 10, true); // return 10
SELECT nextval('sequence_name'::regclass) // return 11なるほど。ということは2番目の引数にnextvalの結果と増やしたい値を足したものを突っ込めばいいのでは?と考え試してみました。
SELECT setval('sequence_name'::regclass, 10, true); // return 10
SELECT setval('sequence_name'::regclass, nextval('sequence_name'::regclass) + 9, true); // return 20
SELECT setval('sequence_name'::regclass, nextval('sequence_name'::regclass) + 9, true); // return 30
SELECT setval('sequence_name'::regclass, nextval('sequence_name'::regclass) + 9, true); // return 40期待通りの結果になりました。nextvalでシーケンスが1進むので、+ 9で10ずつ進んでいます。ちなみに3番目の引数は設定したシーケンスの値が呼ばれたことにするかどうかの指定だそうです。どっちを使うかは好みの問題でしょうか。ということでプログラムからは以下のクエリを発行し、取得した値から逆算して連番を作成しました。※@count の部分はパラメータクエリを使用しています。
SELECT setval('sequence_name'::regclass, nextval('sequence_name'::regclass) + @count, true);例として@countに9を設定し、20が返ってきた場合、20を含む10個分のID (11~20) が一度に取得できたことになります。これをAPIに組み込み実測したところ、大幅な性能向上を達成できました。






